Robots.txt: the essential information
What is the robots.txt file and what is it used for?
Robots.txt is a simple text file at the root of your site (see below) that gives search engines instructions about which areas of a site or which files it should or shouldn’t crawl (see image below). It will not prevent urls from being crawled; to do that it is better to use password protection.
One important function of robots.txt is to inform search engines about the location of your sitemaps, like in the example below:
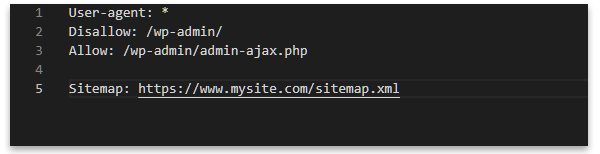
Is a robots.txt file necessary?
Yes! Not only does it give information about which parts of the site are not to be crawled and the location of sitemaps but it is also an indicator of a well-made site. Google, Bing and the other search engines will look for this file on your site and if they don’t find it your site is considered as being of lesser quality. So it needs to be there even if it only has the default information, like this:

NOTE: I have seen examples where there is no line return after “User-agent: *“, in which case the robots will just ignore the directive that follows it.
Where should the robots.txt file be placed?
It should be at the root of your site (at the same level as index.php or index.html) and accessible with the url “https://www.mydomain.com/robots.txt”, replacing the domain name with your own like in the example below for my site:

More information
Google’s developer site has a lot of useful information :
Introduction to robots.txt on developers.google.com
Google’s instructions on how to create the file